Initially published by petites singularités. English translation provided by OW2.
If you want to sign the letter, please publish the letter on your website and complete the table here
Initially published by petites singularités. English translation provided by OW2.
If you want to sign the letter, please publish the letter on your website and complete the table here
Cette lettre a été publiée initialement par les petites singularités. Si vous souhaitez signer la lettre, merci de la publier sur votre site et de compléter le tableau ici.
Cette lettre a été publiée initialement par les petites singularités. Si vous souhaitez signer la lettre, merci de la publier sur votre site et de compléter le tableau ici.
Depuis 2020, les programmes Next Generation Internet (NGI), sous-branche du programme Horizon Europe de la Commission Européenne financent en cascade (via les appels de NLNet) le logiciel libre en Europe. Cette année, à la lecture du brouillon du Programme de Travail de Horizon Europe détaillant les programmes de financement de la commission européenne pour 2025, nous nous apercevons que les programmes Next Generation Internet ne sont plus mentionnés dans le Cluster 4.
Les programmes NGI ont démontré leur force et leur importance dans le soutien à l'infrastructure logicielle européenne, formant un instrument générique de financement des communs numériques qui doivent être rendus accessibles dans la durée. Nous sommes dans l'incompréhension face à cette transformation, d'autant plus que le fonctionnement de NGI est efficace et économique puisqu'il soutient l'ensemble des projets de logiciel libre des plus petites initiatives aux mieux assises. La diversité de cet écosystème fait la grande force de l'innovation technologique européenne et le maintien de l'initiative NGI pour former un soutien structurel à ces projets logiciels, qui sont au cœur de l'innovation mondiale, permet de garantir la souveraineté d'une infrastructure européenne. Contrairement à la perception courante, les innovations techniques sont issues des communautés de programmeurs européens plutôt que nord-américains, et le plus souvent issues de structures de taille réduite.
Le Cluster 4 allouait 27.00 millions d'euros au service de :
Au nom de ces enjeux, ce sont plus de 500 projets qui ont reçu un financement NGI0 dans les 5 premières années d'exercice, ainsi que plus de 18 organisations collaborant à faire vivre ces consortia européens.
NGI contribue à un vaste écosystème puisque la plupart du budget est dévolue au financement de tierces parties par le biais des appels ouverts (open calls). Ils structurent des communs qui recouvrent l'ensemble de l'Internet, du matériel aux applications d'intégration verticale en passant par la virtualisation, les protocoles, les systèmes d'exploitation, les identités électroniques ou la supervision du trafic de données. Ce financement des tierces parties n'est pas renouvelé dans le programme actuel, ce qui laissera de nombreux projets sans ressources adéquates pour la recherche et l'innovation en Europe.
Par ailleurs, NGI permet des échanges et des collaborations à travers tous les pays de la zone euro et aussi avec ceux des widening countries [1], ce qui est actuellement une réussite tout autant qu’un progrès en cours, comme le fut le programme Erasmus avant nous. NGI0 est aussi une initiative qui participe à l’ouverture et à l’entretien de relation sur un temps plus long que les financements de projets. NGI encourage également à l'implémentation des projets financés par le biais de pilotes, et soutient la collaboration au sein des initiatives, ainsi que l'identification et la réutilisation d'éléments communs au travers des projets, l'interopérabilité notament des systèmes d'identification, et la mise en place de modèles de développement intégrant les autres sources de financements aux différentes échelles en Europe.
Alors que les États-Unis d’Amérique, la Chine ou la Russie déploient des moyens publics et privés colossaux pour développer des logiciels et infrastructures captant massivement les données des consommateurs, l’Union Européenne ne peut pas se permettre ce renoncement. Les logiciels libres et open source tels que soutenus par les projets NGI depuis 2020 sont, par construction, à l’opposée des potentiels vecteurs d’ingérence étrangère. Ils permettent de conserver localement les données et de favoriser une économie et des savoirs-faire à l’échelle communautaire, tout en permettant à la fois une collaboration internationale. Ceci est d’autant plus indispensable dans le contexte géopolitique que nous connaissons actuellement. L’enjeu de la souveraineté technologique y est prépondérant et le logiciel libre permet d’y répondre sans renier la nécessité d’œuvrer pour la paix et la citoyenneté dans l’ensemble du monde numérique.
Dans ces perspectives, nous vous demandons urgemment de réclamer la préservation du programme NGI dans le programme de financement 2025.
[1] Tels que définis par Horizon Europe, les États Membres élargis sont la Bulgarie, la Croatie, Chypre, la République Tchèque, l’Estonie, la Grèce, la Hongrie, la Lettonie, la Lithuanie, Malte, la Pologne, le Portugal, la Roumanie, la Slovaquie et la Slovénie. Les pays associés élargies (sous conditions d’un accord d’association) l’Albanie, l’Arménie, la Bosnie Herzégovine, les Iles Feroé, la Géorgie, le Kosovo, la Moldavie, le Monténégro, le Maroc, la Macédoine du Nord, la Serbie, la Tunisie, la Turquie et l’Ukraine. Les régions élargies d’outre-mer sont: la Guadeloupe, la Guyane Française, la Martinique, La Réunion, Mayotte, Saint-Martin, Les Açores, Madère, les Iles Canaries.
Cette revue de presse sur Internet fait partie du travail de veille mené par l’April dans le cadre de son action de défense et de promotion du logiciel libre. Les positions exposées dans les articles sont celles de leurs auteurs et ne rejoignent pas forcément celles de l’April.
le .
Dans une démarche qui vise à regagner en autonomie et à réduire les coûts liés au fonctionnement de ses collectivités territoriales, une région française a décidé de remplacer les solutions des géants du numérique par des alternatives locales et open source.
le .
Une panne informatique géante touche de nombreuses entreprises dans le monde, dont les aéroports. Le géant de la tech Microsoft a déclaré vendredi qu’il était en train de prendre des «mesures d’atténuation».
le .
Cinq ans ou presque après sa création, la Cour des comptes se penche sur la Direction interministérielle du numérique. Elle demande la clarification de sa stratégie et de son budget pour évaluer ses dépenses convenablement. Elle pointe aussi le besoin d’une vigilance dans l’exercice de ses missions historiques que sont la promotion de la donnée publique, assurée par Etalab, et le réseau interministériel de l’État.
le .
La Suisse impose la divulgation du code source des logiciels pour le secteur public, ce qui est une étape importante sur le plan juridique
le .
La neutralité du Net aux États-Unis ressemble un peu au jeu du chat et de la souris avec la FCC. Elle a tout d’abord été instaurée sous la présidence de Barack Obama en 2015. Elle a ensuite été supprimée en 2018 lorsque Donald Trump était président et qu’il avait positionné Ajit Pai à la tête de la FCC.
Le .
Le Guide d’accompagnement du programme de technologie au cycle 4, daté de février 2024, recommande de “privilégier” les logiciels libres dans de nombreuses activités pédagogiques et technologiques. Stefane Fermigier, du CNLL, Conseil National du Logiciel Libre, se réjouit de cette avancée significative dans l’intégration des logiciels libres au sein des programmes éducatifs français. Toutefois, le CNLL regrette que cette évolution ait nécessité 12 ans et que les recommandations concernant les logiciels libres demeurent principalement confinées à l’enseignement technologique.
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Les airbags tueurs, une bombe à retardement ? Si le scandale Takata a entraîné la disparition de l’équipementier japonais en 2017, l’onde de choc continue aujourd’hui encore de se propager partout dans le monde. En cause, des airbags qui se déclenchent de façon intempestive, allant jusqu’à tuer les conducteurices… Les rappels de véhicules se comptent par millions, notamment en France, pour corriger dans les meilleurs délais ce grave problème de sécurité.
Entamé au début du mois, le mouvement de contestation contre les quotas dans la fonction publique continue d’être sévèrement réprimé, laissant place à de violents affrontements à travers le pays.
C’est le déclencheur de la colère des étudiants et les violents affrontements, qui ont fait jusqu’ici 151 morts.[…] Ces quotas réintroduits le mois dernier réservaient 30 % des postes aux enfants des anciens combattants de la guerre de libération du Bangladesh contre le Pakistan, catégorie réputée proche du pouvoir en place.
Le régime de Bachar Al-Assad ne s’est pas contenté d’arrêter, de torturer et de tuer massivement son peuple, il s’est aussi emparé des biens des habitant·es. Avec un triple objectif : remplir les caisses de l’État, enrichir les hauts dignitaires du pouvoir et empêcher tout retour des indésirables — opposants ou supposés tels. Une pile de documents dévoilés lors du procès de Paris en mai 2024 a apporté les preuves de ce nettoyage politico-financier systématique.
Malgré les protestations, le pays dirigé depuis des décennies par la famille Gnassingbé devrait basculer dans un régime parlementaire. Il pourrait permettre au chef de l’État de se maintenir au pouvoir sans aucune limite de temps tant que sa majorité l’emporte. Au grand dam de l’opposition et des citoyens, qui n’ont que peu d’espace pour s’exprimer.
Quelques minutes après l’annonce du retrait de la présidentielle de Joe Biden, sa famille et une poignée de démocrates ont défendu le bilan du 46e président des Etats-Unis, qui a confié le soin à Kamala Harris de représenter son parti face à Donald Trump.

A professional ethical hacker, Noe has 10 implants in various parts of his body that he uses for offensive security purposes. They enable him to bypass security protocols, let himself into buildings and hack into people’s smartphones.
Et en français : Ce hackeur s’est fait implanter des puces dans le corps pour pirater vos comptes (korii.slate.fr)
Parmi les individus qui s’insurgent contre la destruction de l’ISS, on trouve Jean-Jacques Dordain, qui a été le directeur général de l’Agence spatiale européenne (ESA) entre 2003 et 2015. |…] [il] suggère de propulser l’ISS vers une orbite plus élevée, afin que la station soit conservée dans l’espace.
The Israeli port of Eilat officially declared its bankruptcy, after eight months of complete paralysis of commercial activity and its cessation of receiving ships and containers, especially coming from the Asian countries’ markets, carrying with them the needs of the economy and its industrial sector. This includes raw materials, intermediate goods, production inputs, machinery and equipment, crude oil and fuel, wheat, food, cars and other market needs.
« La réalité est que les pires violences n’ont clairement pas été commises par des civils de Gaza » […] Et de souligner, au contraire, « la nature incroyablement planifiée et coordonnée » de l’attaque contre les villes, les kibboutz et les bases militaires dans le territoire israélien entourant Gaza.
VioGén est utilisé par la police pour évaluer la probabilité qu’une victime subisse à nouveau la violence
Les deux joueurs tricolores, mis en examen pour « viol aggravé avec violences en réunion », porteront des bracelets électroniques.
De nombreuses lésions « dans les parties intimes » et « divers hématomes » ont été constatées sur le corps de la jeune femme accusant les deux joueurs du XV de France, d’après un rapport médico-légal présenté devant le parquet de Mendoza (Argentine)
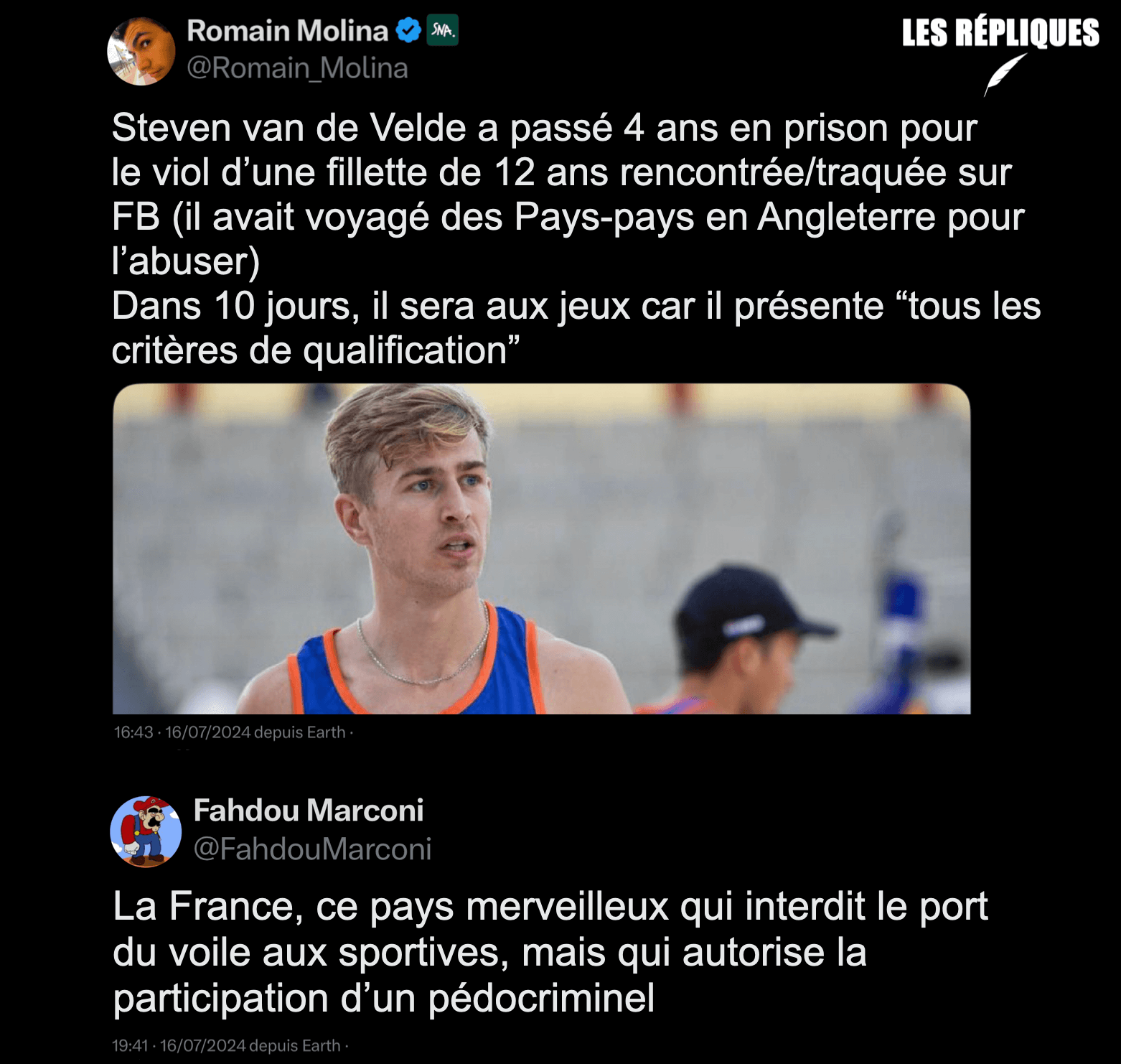
Steven van de Velde a été condamné en 2016 pour le viol d’une fille de 12 ans. Il participera aux JO en se tenant à l’écart de la presse et des autres sportifs, annonce le comité olympique néerlandais.
Défenseuse des droits humains, Amel Hadjadj a participé activement au Hirak, soulèvement populaire démarré en 2019 en Algérie. Le corps et l’âme profondément engagés dans les luttes des femmes et des minorités de genre, elle pose un regard critique sur le cheminement de leurs conditions.
Menacée de mort par les islamistes au début des années 1990, l’athlète de demi-fond apporte à l’Algérie la première médaille d’or de son histoire. Toute sa vie, Hassiba Boulmerka s’est battue pour le droit élémentaire des femmes à êtres libres de courir.
L’État de Puebla, dans le centre du pays, est le 14e à approuver lundi 15 juillet au soir la réforme du Code pénal local éliminant toute sanction pour des IVG jusqu’à douze semaines de grossesse.
Dans un pays fracturé par une crise politique, ces Jeux devront être “pour tout le peuple de France une occasion de concorde fraternelle”, “de renforcer l’unité de la Nation”, a souhaité le pape François.

Pour la première fois, onze groupes ont été constitués au Palais Bourbon. Un seul dépasse les 100 élu·es : celui du Rassemblement National
Nombreux élus, à gauche mais pas uniquement, dénoncent un résultat en forme de « déni de démocratie » et propre à dégoûter les électeurices.
Voir aussi À l’Assemblée nationale, l’élection de Yaël Braun-Pivet face à André Chassaigne vue des coulisses (huffingtonpost.fr) et Élection de la Présidente de l’Assemblée nationale : une journée sous haute tension politique (projetarcadie.com)
La France insoumise a déposé samedi 20 juillet un recours devant la plus haute juridiction administrative du pays, estimant que les 17 ministres démissionnaires n’auraient pas dû participer au scrutin ayant réélu Yaël Braun-Pivet au perchoir.La décision de la juridiction est très incertaine. […] Pour critiquer la participation des ministres à un scrutin au sein de l’Assemblée, les élus du NFP s’appuient sur l’article 23 de la Constitution : « Les fonctions de membre du gouvernement sont incompatibles avec l’exercice de tout mandat parlementaire. » Mais le même article du code électoral termine par une formation qui complique un peu la donne : « L’incompatibilité ne prend pas effet si le gouvernement est démissionnaire avant l’expiration dudit délai. » […] un précédent a déjà eu lieu, avec l’un des gouvernements Rocard sous la présidence Mitterrand en 1988 […] Le Conseil constitutionnel quant à lui, s’est déjà dit incompétent pour statuer sur l’élection du président de l’Assemblée nationale, en 1986 et en 2007. Autre possibilité : « Demander au Conseil constitutionnel de se prononcer non pas sur l’élection mais sur la situation d’incompatibilité des ministres-députés » […] On ignore encore ce que contient le recours déposé par La France insoumise
Le premier tour de l’élection des six vice-présidences a dû être annulé, en raison d’un nombre d’enveloppes supérieur au nombre de votant·es.
À la surprise générale, le Nouveau Front populaire a décroché la majorité des sièges au sein du bureau de l’Assemblée. Une instance peu connue, mais aux pouvoirs importants.
Contrairement à la tradition, les élus du camp présidentiel ont pris part au vote pour ce poste très stratégique et conférant de nombreux pouvoirs. [Coquerel] annonce qu’il démissionnera de cette présidence quand un gouvernement du Nouveau Front populaire se formera. […] Sur les huits commissions que comporte l’Assemblée nationale, six sont désormais présidées par l’ex-majorité macroniste, dont les représentants ont été soutenus par la droite lors des scrutins.
Après avoir obtenu la majorité absolue au bureau et réussi à garder une présidence de commission stratégique, le NFP entend rapidement former un gouvernement.
La présidente de l’Assemblée nationale a dénoncé l’absence du parti d’extrême droite au sein du bureau de l’institution et a accusé le NFP d’en être responsable.
Alors que la CGT, fait rare, s’est engagée dans la campagne en faveur du NFP, sa secrétaire générale Sophie Binet a aussi exhorté les dirigeants de gauche à être « à la hauteur des millions de salariés, de retraités, de jeunes » qui leur ont donné leur voix.

Selon les nouvelles analyses, les concentrations en bactéries Escherichia coli — pouvant provoquer diarrhées et vomissements — sont descendues en dessous des seuils préconisés par l’Anses et les fédérations sportives. Tout comme les concentrations en entérocoques, à l’origine des septicémies ou d’infections urinaires.
À quelques jours des Jeux olympiques de Paris, 60 % des établissements recevant du public en France enfreignent la loi en ne mettant pas de points d’eau à disposition.
Depuis 2005, la multinationale a vendu plus de 18 milliards de bouteilles d’eau sous les marques Contrex, Hépar ou Vittel, dont la qualité équivalait à celle de l’eau du robinet. Mais à un prix près de 100 fois supérieur.
aucun responsable politique ne s’est déplacé pour soutenir les trop nombreuses victimes de racisme depuis ces dernières semaines, ils n’ont pas non plus condamné les appels aux ratonnades : indifférence dont nous nous souviendrons. Aucun crime raciste ou antisémite ne doit plus être passé sous silence.[…] Les grandes perdantes de cette séquence sont les femmes, comme lors de chaque crise. Depuis le 7 juillet, elles sont moins nombreuses à l’Assemblée nationale car peu étaient investies par leurs partis en positions d’éligibilité. Inexistantes dans les débats télévisés, rejetées, même […] Le fascisme c’est aussi le sexisme et les inégalités hommes-femmes, les menaces sur les droits à l’IVG, des agressions justifiées et non punies.
À l’approche des JO à Paris, l’ONG lance un nouvel appel à lever l’interdiction du port du foulard en compétition, qu’elle estime à contre-courant des règlements internationaux.
les hommes français ont été en quelque sorte épargnés par le stress lié à l’empiètement de la famille lors des heures de télétravail, et ce justement grâce à la présence de leur conjointe, pourtant en télétravail elle aussi.
Une infirmière qui avait soigné le religieux en 2006 dans un hôpital militaire d’Ile-de-France témoigne contre lui ce samedi 20 juillet, s’ajoutant à sept autres femmes. En outre, des membres de la Commission indépendante sur les abus sexuels dans l’Eglise admettent avoir eu connaissance de trois cas depuis plusieurs années.
Mais qu’espérer d’un grand oral où les dirigeants de CNews ont dû donner l’illusion de ne pas être à la tête d’une chaîne d’opinion pour continuer à exister sur la TNT ? Car si la ligne éditoriale de CNews n’échappe à personne, d’autant plus ces dernières semaines avec les deux élections successives, tout le monde semblait s’être mis d’accord dans l’assemblée pour éviter le sujet.
« Mediapart » révèle ce mardi 16 juillet la vidéo brute de l’interview de Ziad Takieddine, dont seule une petite partie avait été utilisée par la chaîne d’information, afin de disculper l’ex-Président dans l’affaire du financement libyen de sa campagne de 2007.
Selon le magazine « Challenges », qui publie ce jeudi 18 juillet son classement annuel, la fortune cumulée des 500 plus riches Français dépasse pour la première fois en 2024 les 1 200 milliards d’euros.

La Commission de régulation de l’énergie (CRE) a annoncé ce lundi que le gouvernement renonce finalement à appliquer une augmentation, après celle de juillet. Liée à la revalorisation du tarif d’acheminement du courant, elle devait entraîner une hausse de 1 % des factures. Bercy concède une décision en partie politique.
La plus haute juridiction administrative a rendu une décision supprimant la niche fiscale dont bénéficie les locations sur le modèle d’Airbnb. Cette niche fiscale avait été supprimée par les sénateurs avant d’être réintroduite par le gouvernement. La suppression de cette niche fiscale, votée au Sénat, avait été conservée par erreur par le gouvernement dans la loi de finances de 2024
La fréquentation serait en très forte baisse. Commerçants et restaurateurs pointent notamment du doigt les barrières et le manque d’information des autorités.
Du 20 juillet au 26 juillet, les bateaux marchands et de croisières auront l’interdiction de naviguer sur le fleuve en amont de la cérémonie d’ouverture des Jeux olympiques.[…]la fermeture tombe en pleine période de moissons, où des montagnes de grains d’orge, de blé puis de maïs quittent les fermes pour gagner les ports fluviaux en amont de Paris.
Retour sur les 7 dernières années durant lesquelles les réformes de l’assurance chômage se sont enchaînées, rendant la situation des gens en galère de plus en plus intenable, les nouveautés du début de l’année 2024 et les sombres perspectives de la fin de cette année.
Plusieurs décrets d’application de la loi immigration ont été publiés au Journal officiel mardi 16 juillet. L’un d’entre eux prévoit le refus ou le retrait d’un titre de séjour en cas de non-respect des « principes de la République ». Le texte, adopté en décembre, est décrié par la gauche et les militant·es des droits humains.
Voir aussi Loi immigration : un décret « risque de produire un grand nombre de sans-papiers » (basta.media)
Juste avant l’acceptation de la démission du gouvernement [ce dernier] a publié au JORF une série de décrets […] venant mettre en musique la loi immigration-intégration du 26 janvier 2024, dite « loi Darmanin ». Ils concrétisent dans la partie réglementaire du Code des étrangers (CESEDA) le caractère régressif de ce texte pour les étrangers et demandeurs d’asile.
À la mobilisation des antibassines, Gérald Darmanin poursuit la criminalisation des écologistes comme si les récentes élections n’avaient pas eu lieu. Depuis son ministère tout-puissant, il multiplie les mensonges.

Un campement de 250 personnes exilées a été démantelé par les forces de police au nord de Paris, le 16 juillet. Une nouvelle preuve du « nettoyage social » à l’approche des Jeux olympiques, dénoncent les associations.
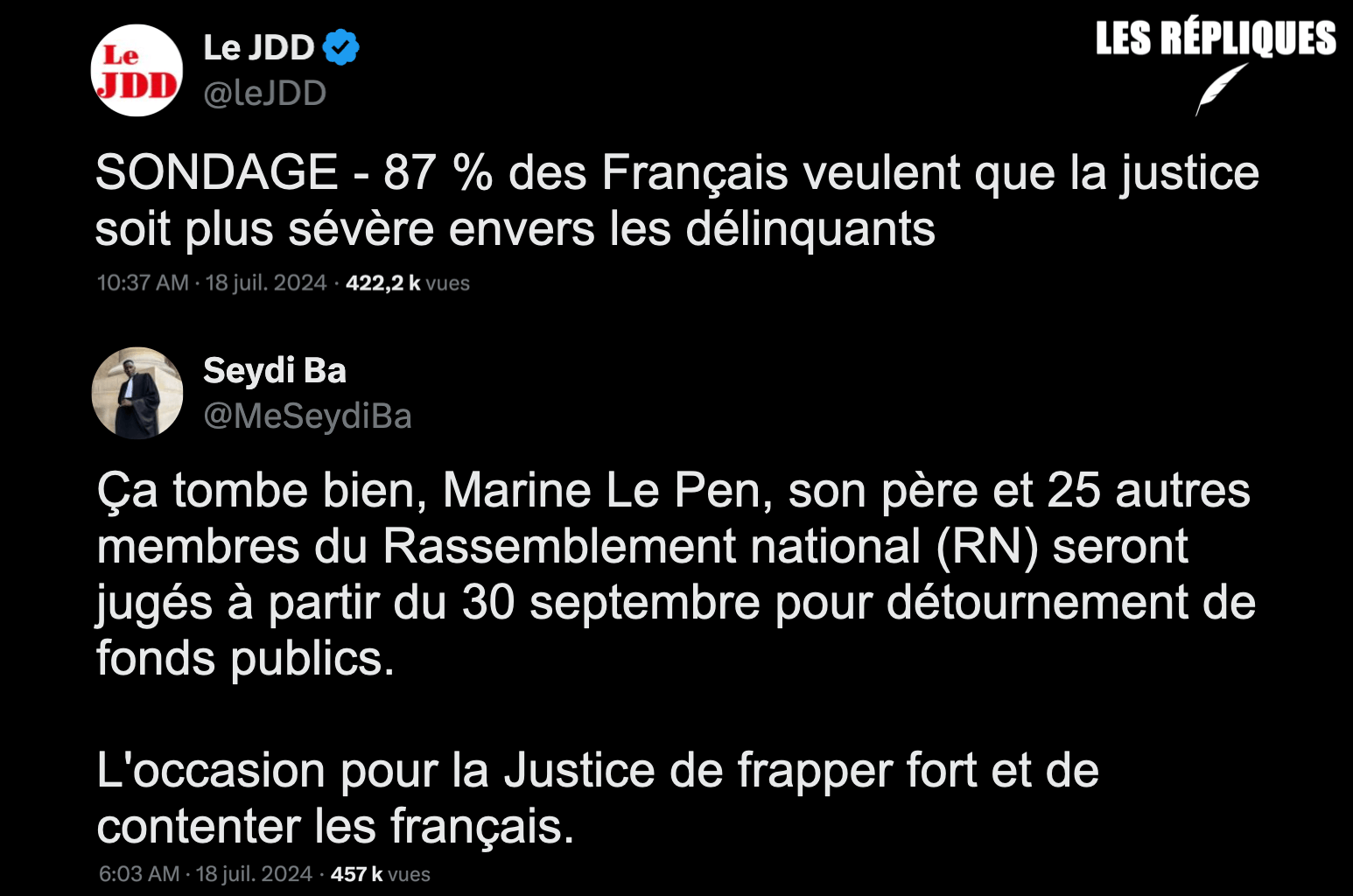
Dix-sept ministres, parmi lesquels Gérald Darmanin, Marc Fesneau et Prisca Thevenot, ont été élus ou réélus députés à l’Assemblée nationale, lors des législatives anticipées. Problème : ils vont participer à des votes très stratégiques de l’institution comme l’élection du président du Palais bourbon, tout en restant, de fait, membres du gouvernement.
Rédigé à la manière d’un business plan de start-up, le document élaboré par le milliardaire Pierre-Édouard Stérin et ses proches au sein de Périclès décrit, étape par étape, l’installation à tous les échelons du pouvoir d’une alliance entre l’extrême droite et la droite libérale-conservatrice. […] Notre projet découle d’un ensemble de valeurs clés (liberté, enracinement et identité, anthropologie chrétienne, etc.) luttant contre les maux principaux de notre pays (socialisme, wokisme, islamisme, immigration). Pour servir et sauver la France, nous voulons permettre la victoire idéologique, électorale et politique. Pour cela, Périclès prévoit de déployer environ 150 millions d’euros sur les dix prochaines années via le financement ou la création de projets.
Un groupuscule identitaire comptait organiser samedi une soirée réservée aux « garçons blancs » dans la préfecture de Côte-d’Or. Elle a été interdite par la mairie, qui dénonçait un événement raciste et xénophobe, puis annulée ce jeudi 18 juillet par les organisateurs.
Dans la nuit du 16 au 17 juillet, un convoi de cyclistes roulant vers les Deux-Sèvres, où se tient un rassemblement antimégabassines, a été violemment attaqué. Bilan : 2 blessé·es, des vélos et tentes volés et des pneus crevés.

« Ils m’ont pris mes bouchons d’oreille car ils nous ont dit que c’était du matériel de protection. Et que cela les empêchait de bien travailler car nous, on n’entendrait plus le bruit des grenades de désencerclement »
Voir aussi “Il n’y a pas une once de violence dans ce qui s’organise” : avant de manifester, des militants anti-bassines se réunissent dans les Deux-Sèvres (francetvinfo.fr)
Il y a quand même une dichotomie entre ce qui est vécu par la préfecture, qui dit qu’il y a eu 400 objets qui ont été saisis. En fait, dans les objets qui ont été saisis, une copine me disait qu’ils ont saisi le casque anti-bruit de sa fille, une autre s’est fait saisir les cales de sa caravane, une autre ses gants de jardin, énumère la manifestante. Moi je pense que c’est une stratégie pour essayer de faire monter la pression, pour essayer de faire apparaître le rassemblement comme violent.
Et La gendarmerie diffuse des photos d’« armes » saisies sur des gens se rendant à la mobilisation contre les méga-bassine, notamment… des cartouches de chasse (threadreaderapp.com)
Un journaliste de Politis a réussi à contacter la personne à qui ces cartouches ont été confisquées : c’est un chasseur qui habite à plus de 100 km, ne milite pas contre les bassines et s’est fait contrôler près de chez lui.
La police des polices a été saisie ce lundi 15 juillet pour faire la lumière sur une vidéo, largement diffusée sur les réseaux sociaux au cours du week-end, montrant un groupe de policiers portant des coups à une personne menottée au sol en région parisienne. Plusieurs personnalités politiques de gauche ont exprimé leur indignation.
L’homme algérien a été tué le 29 juin par un policier hors service, qui lui a tiré six balles dans le corps à Bobigny (Seine-Saint-Denis).
Plusieurs sites de Chase Bank ont cessé leurs opérations en raison d’un lock-out dans le cadre d’une attaque coordonnée à la suite de leurs profits de guerre à Gaza. Le personnel de Chase a été forcé de casser ses propres fenêtres pour entrer dans le bâtiment.
Après la publication de la lettre ouverte d’Emmanuel Macron aux Français, le 10 juillet, la Fédération CGT des cheminots appelle à des rassemblements partout en France le 18 juillet pour le respect du vote des législatives.
Plusieur·es député·es, de gauche mais pas seulement, ont refusé de serrer la main de l’élu RN Flavien Termet lors du vote pour le perchoir jeudi. S’ils ont été la cible de vives critiques, d’autres, y compris de droite, ont déjà agi de la sorte par le passé.[…] En 2012, de nombreux élus avaient déjà refusé de serrer la main de la benjamine de l’époque : Marion Maréchal-Le Pen, alors âgée de seulement 22 ans. Parmi eux : plusieurs députés UMP, dont Jean-François Copé, François Fillon, Bruno Le Maire, Eric Ciotti ou encore Gérald Darmanin.
Alors que l’Arcom étudie ce lundi 15 juillet la réattribution des fréquences TNT pour la chaîne Cnews, une centaine d’organisations syndicales, antiracistes, féministes et écologistes lancent une campagne d’action contre le groupe Bolloré. « Nous devons, sans attendre de prochaines échéances électorales, unir nos force contre les vecteurs de fascisation de la société. Nous appelons en ce sens à mener partout bataille contre Bolloré. »
Voir aussi Les Soulèvements de la terre appellent à « démanteler l’empire Bolloré (off-investigation.fr)
Le Village de l’eau contre les mégabassines dans le Marais poitevin a pris une coloration antifasciste. Les mouvements écologistes cherchent à construire des ripostes locales contre l’extrême droite.
L’établissement des Deux-Sèvres voit mûrir au sein de son BTS gestion et protection de la nature une nouvelle génération d’activistes contre l’accaparement de l’eau. Ses élèves aux parcours sinueux trouvent dans ce terroir et son activité militante le déclic d’un engagement durable.
Le syndicat SFA-CGT veut dénoncer les « criantes inégalités de traitement » entre les artistes recrutés pour le spectacle de la cérémonie.
Après un an de grève, les cinquante travailleureuses sans-papiers des communautés Emmaüs du Nord ont obtenu la condamnation des dirigeant·es de leurs communautés dans le Nord et la régularisation de 47 d’entre elleux.
Les modèles d’art qui œuvrent pour les Ateliers beaux-arts de la ville de Paris se réunissent pour dénoncer le manque de moyens et de considération.
depuis la mise à jour de septembre 2023 de Google (puis de janvier, mars et juin 2024) le trafic organique SEO des sites web s’effondre. Des sites web se sont vus avec des baisses de trafic de +50 % du jour au lendemain.
“No shady privacy policies or back doors for advertisers” proclaims the Firefox homepage, but that’s no longer true in Firefox 128.Less than a month after acquiring the AdTech company Anonym, Mozilla has added special software co-authored by Meta and built for the advertising industry directly to the latest release of Firefox, in an experimental trial you have to opt out of manually.
Selon le ministre (démissionnaire) des Armées, les précautions prises sont suffisantes pour éviter ce genre de bug informatique sur les armées ou le ministère. […] « notre dépendance à Microsoft est telle que le ministère utilise une version obsolète qui empêche l’usage de logiciels de dernière génération. »

Outre-Quiévrain, le système proportionnel oblige les partis à s’entendre sur la base de compromis longuement négociés entre les partis pendant des semaines, voire des mois.
la recherche sur le sans-abrisme a été androcentrée jusque dans les années 2010, c’est-à-dire qu’elle avait pour référentiel une grille de lecture essentiellement masculine. Enfin, il n’existe quasiment aucun travail croisant le genre (c’est-à-dire les rapports sociaux entre les sexes, marqués par des inégalités, des hiérarchies souvent en défaveur des femmes) avec le secteur de l’insertion ou de l’économie solidaire en France. […] Il y a eu une division du travail militant selon le sexe. L’abbé Pierre a occupé le devant de la scène politique et médiatique, tandis que Lucie Coutaz a joué un rôle crucial d’administration et de gestion des structures créées, « dans l’ombre d’un autre » comme le rappelait l’abbé lui-même, en saluant son tempérament de cheffe. […] Au départ, l’abbé Pierre a agi avec et pour des hommes, marginaux, accueillis dans des Communautés uniquement masculines… Ces derniers retrouvaient une dignité par le travail, et par le service des « plus souffrants » qu’eux. Or ces plus souffrants étaient notamment les familles sans domicile, donc en réalité, souvent des femmes accompagnées d’enfants, recevant l’aide matérielle des Compagnons bâtisseurs, ou l’aide financière de chiffonniers. […] Souvent, on fait de la présence de femmes ou de familles à la rue un phénomène nouveau, qui s’accroit de manière spectaculaire, mais la question des chiffres et de leur médiatisation est complexe. On peut parler d’un déni d’antériorité de la présence des femmes à Emmaüs, invisibilisées parfois par le terme de « famille » ou les termes universalistes de « personnes en situation de précarité ».
Le nombre d’élèves en situation de handicap scolarisés augmente. Mais le manque de moyens, de personnels, de politiques de long terme freine l’inclusion scolaire.
À propos de : Josiane Boutet – Marcel Cohen, linguiste engagé dans son siècle (1884-1974) Ce savant engagé voyait dans la langue un objet social éminemment politique, objet de rapports de force, de pouvoir, et donc d’émancipation.
Non seulement, Veesion se vante de faire du business sur la détresse sociale mais leur logiciel est également illégal. D’autant qu’il n’est pas certain que cet algorithme existe réellement.
À propos de : David Robinson, Voices in the code. A story about people, their values, and the algorithm they made
Une étude scientifique […] documente l’effet surprenant de cette violente dépression le 2 novembre 2023 sur la préparation du thé dans une large partie sud-est du pays, notamment à Londres. […] « Je ne m’attendais pas à ce qu’un orage fasse sortir la température de l’eau bouillante de la fourchette recommandée pour préparer un thé décent. La météo peut avoir des effets subtils »
Aussitôt installés dans leur résidence CROUS de Paris, certains agents de police ont eu quelques surprises : moisissures, crottes de souris, cafards. Les syndicats jugent ces conditions de logement inacceptables. Une réalité pourtant dénoncée par les étudiants boursiers depuis des années.

« Caffre » en français, « caffre » ou « kafir » en anglais, « cafre » en espagnol et en portugais : le mot a désigné, pour les colonisateurs européens, une partie des populations noires africaines depuis le début du XVIe siècle. Dans ce mot qui a survécu jusqu’à nos jours […] se trouve tout un imaginaire profondément empreint de racisme et de justification de la supériorité blanche.

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
Le vendredi 21 juin, le Conseil d’État a rendu une ordonnance de référé passée presque inaperçue concernant Veesion, la start-up française de surveillance algorithmique des « vols » en supermarchés. Bien qu’il s’agisse d’une procédure toujours en cours (l’affaire doit encore être jugée au fond), la justice administrative a conforté ce que nous soulignons depuis 3 ans : l’illégalité du logiciel conçu par la start-up de surveillance.
Autre fait passé inaperçu : la délocalisation à Madagascar d’une partie de travail de Veesion – et la possible remise en cause de l’authenticité de son algorithme.
La surveillance algorithmique, ce n’est pas que pour nos rues, villes, espaces publics. Comme les caméras, ces dispositifs de surveillance s’étendent, se normalisent et s’insinuent petit à petit dans nos quotidiens. Veesion est une start-up française qui vend un logiciel de surveillance algorithmique pour soi-disant détecter les vols en supermarché.
Concrètement, il s’agit d’installer sur les caméras des supermarchés un algorithme repérant des gestes considérés comme suspects pour détecter les « mauvaises intentions de possibles voleurs à l’étalage » (pour reprendre l’expression d’un publi-reportage de la société par le journal d’extrême-droite le JDD).
L’objectif est purement financier : promettre à ses clients (des grandes ou petites surfaces) une réduction de « plus de 60% des pertes liées au vol à l’étalage » et de sauver « 1 à 3% du chiffre d’affaires » qui leur serait subtilisé. Dans sa présentation en 2021 (sur un post Medium aujourd’hui supprimé), le créateur de Veesion allait plus loin : son logiciel devait protéger la grande distribution des troubles sociaux à venir du fait de la détresse sociale (comprendre : protéger les grandes surfaces des populations pauvres poussées au vol par la situation économique).
Le problème est double. Non seulement, Veesion se vante de faire du business sur la détresse sociale mais leur logiciel est également illégal. D’autant qu’il n’est pas certain que cet algorithme existe réellement.
La Quadrature du Net avait tiré la sonnette d’alarme dès le début : en surveillant les gestes de ses clients, la start-up analyse des données comportementales – dites biométriques – particulièrement protégées au niveau du droit français et européen. Un tel traitement est par principe interdit par l’article 9 du RGPD et l’article 6 de la loi Informatique et Libertés, et les exceptions à cette interdiction sont strictes. Or, aucune de ces conditions n’est applicable au dispositif de Veesion, qui bafoue donc cette interdiction.
Nous n’étions pas les seul·es à relever l’illégalité de Veesion : la CNIL l’avait dit (via plusieurs médias – en se fondant sur un motif d’illégalité différent), tout comme le ministère de l’intérieur. Même Veesion le savait. Bref, tout le monde savait que le logiciel développé par Veesion ne respectait pas le droit en vigueur (pour plus de détails, voir notre analyse de 2023)
Veesion n’a pourtant pas semblé être inquiétée le moins du monde. Pire encore, ces dernières années, elle attire des subventions, reçoit des prix, fait de la publicité dans les journaux, récupère des centaines de clients… Sur son site, Veesion parle même de milliers de commerçants. Un des co-fondateurs, Benoît Koenig, passe sur les plateaux de BFM, affirmant la légalité de son dispositif. En mars 2023, la start-up lève plus de 10 millions d’euros. En juin 2024, elle annonce plus de 150 salariés et plus de 8 millions de chiffre d’affaires.
Après plusieurs années d’indécence, la récente ordonnance du Conseil d’Etat vient révéler que la CNIL a engagé une procédure contre Veesion en raison de l’illégalité de son logiciel. La CNIL a notamment souhaité en alerter l’ensemble de ses clients en obligeant à afficher dans les magasins concernés une information sur une telle infraction à la loi. Veesion a essayé de faire suspendre en urgence cette procédure et le Conseil d’Etat a rejeté la requête le 21 juin dernier.
Prenons les bonnes nouvelles où elles sont : c’est un petit coup d’arrêt à la vidéosurveillance algorithmique dans les supermarchés. À la veille des Jeux Olympiques, célébrations de la normalisation de l’algorithmisation de la surveillance publique, c’est un point positif à conserver.
Difficile néanmoins d’être entièrement convaincu·es.
Si nous n’avons pas accès à la décision de la CNIL, il est fort problable que celle-ci ait considéré le logiciel de Veesion illégal uniquement parce que les client·es des magasins ne peuvent pas s’opposer au traitement de leur image. Ce motif d’illégalité était déjà rappelé par la CNIL dans sa position de 2022 sur la VSA mais nous parait très limité sur le plan politique. C’est en effet une bien faible victoire qui empêche de remettre en cause le fondement même de l’algorithme et son aspect disproportionné et problématique. Non seulement la décision du Conseil d’État est une décision prise dans une procédure d’urgence (il reste à attendre la décision sur le fond de l’affaire qui arrivera dans plusieurs mois) et, de surcroît, Veesion a annoncé depuis que la CNIL avait pour l’instant suspendu sa décision en attente de nouveaux éléments de la part de l’entreprise.
Cette décision ne mettra de toute façon pas à terre plusieurs années de normalisation de ce logiciel. Personne ne demandera aux fondateurs de Veesion et à leurs associés de rembourser l’argent qu’ils ont touché sur leur business sordide. Personne ne viendra compenser les droits et libertés des personnes qui auront été espionné·es ou identifi·eés par cet algorithme. Alors même que les garde-fous contre la surveillance s’amenuisent petit à petit, les maigres barrières qui nous restent sont allégrement méprisées par ces entreprises de surveillance.
C’est d’ailleurs sans aucun doute une stratégie réfléchie, avec laquelle l’écosystème du business numérique s’accorde bien : normaliser une pratique illégale pour créer et asseoir un marché puis attendre du droit qu’il s’adapte à un état de fait, arguant de la création d’emplois et de l’innovation apportée. Lors de la consultation publique lancée par la CNIL sur le sujet en 2022, Veesion plaidait pour sa cause et expliquait à quel point cela serait un drame économique que de freiner cette technologie, sans jamais questionner ses conséquences sur les libertés.
Veesion semble être aussi passée à autre chose et cherche déjà à s’exporter aux États-Unis où le droit à la vie privée et la protection des données personnelles sont encore moins respectés. Médiatiquement, la décision du Conseil d’État ne semble aussi faire que peu de bruit – alors même que les supermarchés clients de Veesion sont nombreux, comme Carrefour, Leclerc ou BioCoop.
Un autre problème pour Veesion a été soulevé par les recherches effectuées par deux sociologues, Clément Le Ludec et Maxime Cornet, chercheurs à Télécom Paris, spécialistes sur le domaine de l’intelligence artificielle. Dans un article sur France Info passé lui-aussi relativement inaperçu (décidemment), les deux chercheurs sont revenus sur la sous-traitance à des travailleur·euses sous-payé·es dans des pays comme Magadascar par l’écosystème de l’IA. Les chercheurs s’inquiètent en particularité de la précarité de ces « travailleurs en bout de chaîne ».
L’article de France Info va plus loin : des personnes ayant été employées à Madagascar pour une société semblable à celle de Veesion disent avoir pour travail de repérer des vols en supermarchés directement sur le flux de vidéosurveillance des magasins : « Notre objectif c’est de trouver les vols. Ce sont eux qui envoient les vidéos, nous on les traite juste. En direct, en temps réel. Nous on envoie juste l’alerte et eux ils font l’arrestation des suspects ». Même si la société s’en défend, Veesion elle-même ne semble pas chercher à Madagascar des personnes pour améliorer un algorithme existant, mais au contraire pour « signaler des vols (…) dans les magasins le plus rapidement possible » ou pour « avertir le magasin d’un comportement douteux ».
En d’autres termes : il est possible que, pour une partie des clients de Veesion, il n’y ait pas vraiment d’algorithme pour repérer des comportements suspects dans un supermarché… mais seulement un·e travailleur·se précaire à l’autre bout du monde chargé·e de visionner le flux de caméra en direct et de repérer « à la main » ces gestes suspects, en imitant l’algorithme. En somme, la fable du turc mécanique.
Cela rejoint le travail des mêmes chercheurs publié en 2023 concernant une société de surveillance en supermarché non explicitement nommée mais qui ressemble beaucoup à Veesion. Clément Le Ludec et Maxime Cornet révèlent, concernant cette société, que les personnes employées à Madagascar « agissent avant tout comme des agents de sécurité à distance, détectant les vols presque en temps réel ».
À noter que Veesion s’appuie sur une double exploitation. Si une grande partie repose sur des personnes exploitées à Madagascar, les caissières et caissiers deviennent aussi des « travailleurs du clic ». Comme l’avait écrit lundimatin dans son article sur l’entreprise, le gérant du magasin conserve en effet le détail des interactions sur les écrans des employé·es, afin de vérifier leur réactivité aux alertes du logiciel : « Libre à lui alors de sommer ses employés d’être plus attentifs aux alertes de la machine en cas de non-retour de leur part ».
Il y a dans la société Veesion le concentré des dérives des start-ups sur le marché du numérique : banalisation des technologies de surveillance, non-respect affiché du droit, dépendance à de la main d’œuvre exploitée à l’autre bout du monde, et forte approximation autour de l’effectivité de son logiciel. Un tel exemple vient interroger l’effectivité du droit comme encadrement. Ces entreprises ne le respectent pas et récoltent pourtant une importante aide financière et médiatique.
Quand un cadre juridique n’est ni respecté par les entreprises concernées, ni appliqué par l’autorité qui en est responsable (ici, la CNIL agit mollement plusieurs années après la mise en œuvre du logiciel), c’est bien l’interdiction explicite de ces systèmes de surveillance qui doit primer. Alors pour agir et vous informer contre la VSA, rendez vous sur laquadrature.net/vsa ou aidez-nous si vous le pouvez en nous faisant un don.
L'April signe cette lettre ouverte adressée à la Commission européenne afin qu'elle maintienne le financement des logiciels libres, à travers les programmes Next Generation Internet (NGI).
Cette lettre a été publiée initialement par les petites singularités. Si vous souhaitez la signer, merci de la publier sur votre site et de compléter le tableau ici.
Lettre ouverte à la Commission européenne
Depuis 2020, les programmes Next Generation Internet (NGI), sous-branche du programme Horizon Europe de la Commission européenne financent en cascade (notamment, via les appels de NLnet) le logiciel libre en Europe. Cette année, à la lecture du brouillon du Programme de Travail de Horizon Europe détaillant les programmes de financement de la commission européenne pour 2025, nous nous apercevons que les programmes Next Generation Internet ne sont plus mentionnés dans le Cluster 4.
Les programmes NGI ont démontré leur force et leur importance dans le soutien à l’infrastructure logicielle européenne, formant un instrument générique de financement des communs numériques qui doivent être rendus accessibles dans la durée. Nous sommes dans l’incompréhension face à cette transformation, d’autant plus que le fonctionnement de NGI est efficace et économique puisqu’il soutient l’ensemble des projets de logiciel libre des plus petites initiatives aux mieux assises. La diversité de cet écosystème fait la grande force de l’innovation technologique européenne et le maintien de l’initiative NGI pour former un soutien structurel à ces projets logiciels, qui sont au cœur de l’innovation mondiale, permet de garantir la souveraineté d’une infrastructure européenne. Contrairement à la perception courante, les innovations techniques sont issues des communautés de programmeurs européens plutôt que nord-américains, et le plus souvent issues de structures de taille réduite.
Le Cluster 4 allouait 27.00 millions d’euros au service de :
- « Human centric Internet aligned with values and principles commonly shared in Europe »1 ;
- « A flourishing internet, based on common building blocks created within NGI, that enables better control of our digital life »2 ;
- « A structured eco-system of talented contributors driving the creation of new internet commons and the evolution of existing internet commons »3.
Au nom de ces enjeux, ce sont plus de 500 projets qui ont reçu un financement NGI0 dans les 5 premières années d’exercice, ainsi que plus de 18 organisations collaborant à faire vivre ces consortia européens.
NGI contribue à un vaste écosystème puisque la plupart du budget est dévolu au financement de tierces parties par le biais des appels ouverts (open calls). Ils structurent des communs qui recouvrent l’ensemble de l’Internet, du matériel aux applications d’intégration verticale en passant par la virtualisation, les protocoles, les systèmes d’exploitation, les identités électroniques ou la supervision du trafic de données. Ce financement des tierces parties n’est pas renouvelé dans le programme actuel, ce qui laissera de nombreux projets sans ressources adéquates pour la recherche et l’innovation en Europe.
Par ailleurs, NGI permet des échanges et des collaborations à travers tous les pays de la zone euro et aussi avec les widening countries [1:1], ce qui est actuellement une réussite tout autant qu’un progrès en cours, comme le fut le programme Erasmus avant nous. NGI est aussi une initiative qui participe à l’ouverture et à l’entretien de relation sur un temps plus long que les financements de projets. NGI encourage également à l’implémentation des projets financés par le biais de pilotes, et soutient la collaboration au sein des initiatives, ainsi que l’identification et la réutilisation d’éléments communs au travers des projets, l’interopérabilité notamment des systèmes d’identification, et la mise en place de modèles de développement intégrant les autres sources de financements aux différentes échelles en Europe.
Alors que les États-Unis d’Amérique, la Chine ou la Russie déploient des moyens publics et privés colossaux pour développer des logiciels et infrastructures captant massivement les données des consommateurs, l’Union européenne ne peut pas se permettre ce renoncement. Les logiciels libres et open source tels que soutenus par les projets NGI depuis 2020 sont, par construction, à l’opposée des potentiels vecteurs d’ingérence étrangère. Ils permettent de conserver localement les données et de favoriser une économie et des savoirs-faire à l’échelle communautaire, tout en permettant à la fois une collaboration internationale. Ceci est d’autant plus indispensable dans le contexte géopolitique que nous connaissons actuellement. L’enjeu de la souveraineté technologique y est prépondérant et le logiciel libre permet d’y répondre sans renier la nécessité d’œuvrer pour la paix et la citoyenneté dans l’ensemble du monde numérique.
Dans ces perspectives, nous vous demandons urgemment de réclamer la préservation du programme NGI dans le programme de financement 2025.
Les vacances approchent, vous allez peut-être voyager, vous balader ou simplement vous livrer à un doux farniente. Pour accompagner votre été que diriez-vous d'écouter (ou réécouter) des podcasts de Libre à vous !, l'émission de l'April sur radio Cause Commune.
À votre disposition 215 émissions et 6 émissions musicales, découpées en plusieurs sujets disponibles individuellement (d'une dizaine de minutes à une heure), pour en apprendre plus sur les enjeux et l’actualité du logiciel Libre, sur les actions de l'April, et comment agir avec elle, et pour vous permettre de prendre le contrôle de vos libertés informatiques ! Sur un chemin de randonnée, dans votre lit, au camping au ailleurs, « bref, c'est Libre à vous ! ».
Au programme : des parcours libristes, Mastodon, jeux vidéos, Drupal, diversité de genre, le travail parlementaire, les actions et le fonctionnement de l'April, l'Éducation nationale, les services libres et loyaux, science ouverte, la libération de code, l'accessibilité, l'achat de matériel, le financement de projets, la Gendarmerie nationale, l'ANSSI, les stratégies logiciel libre d'entreprises, les espaces publics numériques, logiciel libre et collectivités, entreprises, associations, le métier du développement logiciel libre, téléphonie mobile et libertés, les distributions GNU/Linux, l'Open Bar Microsoft/Défense, les GULL (Groupes d'utilisateurs et d'utilisatrices de logiciel libre), les données publiques, Wikipédia, Framasoft, Open Food Facts, OpenStreetMap, les DRM (menottes numériques), la formation, l'apprentissage de la programmation, la santé, système d’information géographique libre, démarches de sensibilisatio, sentiers de randonnée, PostgreSQL, Aaron Swartz, des projets de loi, les géocommuns, œuvres littéraires libres, des musiques libres… et les chroniques de notre équipe.
Et deux nouveautés de la saison radiophonique qui se termine :
Bonne écoute et bonnes vacances à celles et ceux qui en prennent.
Bande annonce de l'émission
Découvrez en 1 minute et 30 secondes
l'émission Libre à vous !
C'est quoi un podcast ?
Un podcast audio est un fichier numérique, disponible sur Internet, permettant d'écouter son contenu (une émission de radio par exemple) n’importe où et n’importe quand.
En vous abonnant au flux de données du podcast, toutes les nouvelles diffusions sont notifiées automatiquement sur votre appareil de lecture (ordinateur, téléphone mobile…). Et vous pouvez écouter le contenu et aussi le télécharger.
Comme lecteur, vous pouvez par exemple utiliser AntennaPod sur Android, ou GPodder, qui est disponible sur plusieurs plateformes. Wikipédia propose une liste de lecteurs.
Tous les podcasts par émission et également par sujet disponibles sur cette page avec un aperçu du programme de l'émission.
Les images d'illustration
L'image avec la voiture a été réalisée par Antoine Bardelli.
L'image avec les trois personnages qui randonnent a été réalisée par Arnaud Champollion.
Les deux images sont diffusées selon les termes d’au moins une des licences suivantes : licence Art libre version 1.3 ou ultérieure, licence Creative Commons By Sa version 2.0 ou ultérieure, licence GNU FDL version 1.3 ou ultérieure.
Libre à vous !, l’émission de l’April, l’association de promotion et de défense du logiciel libre. Prenez le contrôle de vos libertés informatiques, découvrez les enjeux et l’actualité du libre.
Au programme de la 215e émission :
Plus de trois ans après notre recours, le tribunal administratif d’Orléans vient de confirmer que l’audiosurveillance algorithmique (ASA) installée par l’actuelle mairie d’Orléans – des micros installés dans l’espace public et couplés à la vidéosurveillance, destinés à repérer des situations dites anormales – est illégale. Ce jugement constitue la première victoire devant les tribunaux en France contre ce type de surveillance sonore et constitue un rappel fort des exigences en matière de droits fondamentaux pour les autres communes qui seraient tentées par de tels dispositifs.
La ville d’Orléans et l’entreprise Sensivic se sont vu rappeler la dure réalité : déployer des micros dans l’espace public pour surveiller la population n’est pas légal. Les allégations de Sensivic d’un soi-disant produit « conforme RGPD » et les élucubrations d’Orléans en défense pour faire croire qu’il ne s’agirait que d’un inoffensif « détecteur de vibrations de l’air » n’auront servi à rien.
Dans son jugement, le tribunal administratif est sévère. Il commence par battre en brèche l’argument de la commune qui affirmait qu’il n’y avait pas de traitement de données personnelles, en rappelant que les dispositifs de micros couplés aux caméras de vidéosurveillance « collectent et utilisent ainsi des informations se rapportant à des personnes susceptibles, au moyen des caméras avec lesquelles ils sont couplés, d’être identifiées par l’opérateur ». Il en tire alors naturellement la conclusion que ce dispositif est illégal parce qu’il n’a pas été autorisé par la loi.
Mais le tribunal administratif va plus loin. Alors que l’adjoint à la commune d’Orléans chargé de la sécurité, Florent Montillot, affirmait sans frémir que cette surveillance permettrait de « sauver des vies », la justice remet les pendules à l’heure : « à […] supposer [le dispositif d’audiosurveillance algorithmique] utile pour l’exercice des pouvoirs de police confiés au maire […], il ne peut être regardé comme nécessaire à l’exercice de ces pouvoirs ». Autrement dit : « utilité » ne signifie ni proportionnalité ni légalité en matière de surveillance. Cela va à rebours de tout le discours politique déployé ces dernières années qui consiste à déclarer légitime tout ce qui serait demandé par les policiers dès lors que cela est utile ou plus simple sur le terrain. Cela a été la justification des différentes lois de ces dernières années telle que la loi Sécurité Globale ou la LOPMI.
Ce jugement est un avertissement pour les promoteurs de cette surveillance toujours plus débridée de l’espace public. Si la vidéosurveillance algorithmique (VSA) reste la technologie la plus couramment utilisée – illégalement, sauf malheureusement dans le cadre de la loi JO – l’audiosurveillance algorithmique (ASA) n’est pas en reste pour autant. Avant la surveillance à Orléans par Sensivic, on l’a retrouvée à Saint-Étienne grâce à un dispositif d’ASA développé par Serenicity que la CNIL avait lourdement critiqué et fait mettre à l’arrêt.
Avec ce jugement, le tribunal administratif d’Orléans ne déclare pas seulement l’ASA illégale : il estime également qu’un contrat passé entre une commune et une entreprise pour mettre en place ce type de surveillance peut-être attaqué par une association comme La Quadrature. Cet élément est loin d’être un détail procédural, alors que des communes comme Marseille ont pu par le passé échapper au contrôle de légalité de leur surveillance en jouant sur les règles très contraignantes des contentieux des contrats.
En septembre 2023, la CNIL, que nous avions saisie en parallèle du TA d’Orléans, considérait que cette ASA était illégale dès lors qu’elle était couplée à la vidéosurveillance en raison de la possibilité de « réidentifier » les personnes. Mais elle ajoutait qu’elle ne trouvait plus rien à redire depuis que le dispositif orléanais était découplé de la vidéosurveillance locale. Une analyse que nous avons contestée devant le TA d’Orléans1Voir nos observations d’octobre 2023 et celles de janvier 2024..
Dans son jugement, le tribunal administratif d’Orléans n’a pas explicitement considéré que l’ASA orléanaise ne serait pas un traitement de données si elle n’était plus couplée à la vidéosurveillance. Puisqu’il était saisi de la légalité de la convention entre Sensivic et Orléans, laquelle prévoyait ce couplage, il s’est borné à dire que le dispositif ASA et vidéosurveillance était illégal.
Dans tous les cas, ce point est annexe : l’audiosurveillance algorithmique exige, par nature, d’être couplée avec une source supplémentaire d’information permettant de traiter l’alerte émise. Que ce soit par un couplage avec la vidéosurveillance ou en indiquant à des agent·es de police ou de sécurité de se rendre à l’endroit où l’événement a été détecté, l’ASA visera toujours à déterminer la raison de l’alerte, donc d’identifier les personnes. Elle est donc par nature illégale.
Impossible toutefois de passer sous silence la lenteur de l’administration (ici, la CNIL) et de la justice devant les dispositifs de surveillance manifestement illégaux de l’industrie sécuritaire. Alors même qu’un dispositif semblable avait été explicitement et très clairement sanctionné à Saint-Étienne en 2019, Sensivic a pu conclure sans difficulté une convention pour installer ses micros dopés à l’intelligence artificielle. Il aura fallu une double saisine de la part de La Quadrature pour mettre un terme à ce projet.
Un tel dossier prouve que l’industrie sécuritaire n’a que faire du droit et de la protection des libertés, qu’elle est prête à tout pour développer son marché et que l’État et le monde des start-ups s’en accommode bien. Comment Sensivic, avec une technologie aussi manifestement illégale, a-t-elle pu récolter 1,6 millions en 2022, dont une partie du fait de la BPI (Banque Publique d’Investissement) ? L’interdiction explicite de ces technologies de surveillance est la seule voie possible et tenable.
Ce jugement reste une victoire sans équivoque. Il annonce, nous l’espérons, d’autres succès dans notre combat juridique contre la Technopolice, notamment à Marseille où notre contestation de la VSA est toujours en cours de jugement devant la cour administrative d’appel. Alors pour nous aider à continuer la lutte, vous pouvez nous faire un don ou vous mobiliser dans votre ville.
References
| ↑1 | Voir nos observations d’octobre 2023 et celles de janvier 2024. |
|---|


Faire connaître & promouvoir les alternatives aux GAFAMs (Vous connaissez sans doute Google, Apple, Facebook, Amazon : se sont les quatre grandes firmes américaines (nées dans les dernières années du xxe siècle ou au début du xxie siècle sauf Apple créé en 1976) qui dominent le marché du numérique, parfois également nommées les Big Four. Ce sigle, cependant, tend à être abandonné au profit du sigle GAFAM, le M signifiant Microsoft. Leur puissance tend à être contestée par les Natu) :
Voici donc les sujets abordés dans le présent Autonews 🙂 ... "propulsé" par le logiciel libre MOONMOON !
Sauf mentions contraires, le contenu des billets de cet "Autonews" est diffusé sous licence Creative Commons (ou équivalente). Les images & vidéos sont quant à elles diffusées sous leurs licences respectives (libres je l'espère). Je m'efforce de diffuser exclusivement du contenu sous licence libre... Si nécessaire / en cas de doute, faites-moi signe et je ferais le nécessaire.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}